
我为什么要开发Kyanos
kyanos 地址:github.com/hengyoush/kyanos
你有没有遇到过这样的问题 ?
你刚入职新公司,负责一个后端服务,一切都很顺利~
在一个星期五下午5点,还有一个小时你就下班了,但这时~麻烦来了,你的上游突然气势汹汹地找你😡,问你的接口为什么调用超时?
你慌了😩但强作镇定查看监控,发现自己服务的接口耗时正常
在你刚想回怼他之前你突然想到公司的监控 仅能监控到服务端应用的耗时, 可中间内核和网络的耗时没有监控!
于是你们谁也说服不了谁👿, 接下来开始互相扯皮甩锅,最后问题不了了之。。。反过来,你调用下游接口超时,但对方监控显示并没有超时,于是又开始新的扯皮流程,不同的是你站在了另一边…
所以要解决这个问题该怎么办呢?
-
tcpdump抓包! 但tcpdump最大的一个劣势就是排查:太 慢 了。
比如说你现在需要排查一个线上问题:
a. 首先你需要在生产环境安装一个 tcpdump 💤,
b. 然后找到出现问题的服务端的 ip 和 port👁👁
c. 然后自己写过滤表达式(可能你忘了怎么写,花了5min在搜索~😂)
d. 费了九牛二虎之力你终于从生产机器上下载下来一个数百 MB 的 pcap 文件💤
e. 然后安装 tcpdump 客户端(如果你还没安装的话)💤
f. 加载pcap文件让你的CPU风扇狂转 😡
g. 几分钟后你睁大双眼👁👁人肉确认你想要的那个接口在不在这这个pcap文件里,因为包含了太多无效信息,可不幸的是你发现根本没有🤡。。。
h. 然后你重新开始抓包,检查自己的tcpdump命令是否写对… 😔 -
让运维装监控啊! 幸好现在出现了eBPF这一强大的技术,可以深入采集内核打点实现全栈的可观测性。 现在的skywalking、pixie、deepflow等都有着不错的产品。
但这可不容易!上述这些监控要么需要很高的内核版本(5.x),要么只能监控K8s的流量,要么会产生每小时TB级的监控数据需要很重的存储依赖。
那么有没有一款轻量级、兼容低版本内核、并且能高效率的排查 网络问题的工具呢?
kyanos来了!
what is kyanos
kyanos 是我开源的一个命令行工具👉kyanos 仓库地址👈,它支持最低3.10版本的内核,不需要安装任何依赖就可运行,你需要做的只是下载它的可执行文件(Release下载地址)。
那么kyanos的功能是什么?
在详细介绍之前,上一个例子让大家了解kyanos
你不需要了解任何过滤语法,你只需要执行一行命令(kyanos stat http ...),kyanos就能找到最慢的几个 HTTP 请求,并且发现它们耗时详情(想一想如果使用 tcpdump 会花费多少时间):

这里一行命令就找到了几个最慢的请求。
如果你想打印请求响应的内容怎么办呢?,你可以这样:
可以看到请求响应内容直接打印出来了。
kyanos 不仅仅安装特别方便,而且用起来特别符合咱们业务开发的排查模式~ 因为kyanos不是基于数据包维度的,这种粒度太细。通常包含大量无效信息,不适合快速排查问题,而kyanos:完全无侵入,基于七层协议维度,能够过滤大量无效信息,保留对排查问题最有价值的信息。
那么 kyanos 它具体能够做什么呢? kyanos 的主要功能包括两点:
1、 抓取各种协议(HTTP、MySQL、Redis等)的请求响应。
2、 通过聚合 1 中抓取的流量进行更高维度的分析。
这里我不做过多介绍,直接上例子!🤞
细致入微–watch
watch命令可以使用各种过滤条件抓取各种协议(HTTP、MySQL、Redis等)的请求响应。你不需要了解任何过滤表达式的知识就能轻松抓取你想要的任何请求响应进行分析。
比如你有一个Spring Cloud应用,监控告警发现访问远程一个接口 /foo/bar 有时候有一些p99尖刺(比如超过了1s的请求),说明有一些长尾请求,这时你该如何确定问题的根因呢?
很简单,通过kyanos 的 watch 命令查看那些超过1s耗时的请求具体耗时在哪:
kyanos watch http --pid {your_pid} --latency 1000 --path /foo/bar它会输出类似下面的结果:

可以看到watch会输出下面几个部分:
- 请求响应的内容(注:如果太长超过1024字节会截断)。
- 总耗时,即用户发起请求到接收完所有响应的耗时。
- 内核及外部耗时:包括从 socket 缓冲区读取响应的耗时 以及 网络耗时(请求到达网卡 到 响应从网卡接收完毕的耗时)
- 系统调用部分:包括进行了多少次读写系统调用以及读写的字节数量。
可以看到kyanos不仅支持请求响应的内容抓取,甚至把网络和内核的耗时都计算出来了,对排查问题是非常有帮助的!
目前watch支持HTTP、MySQL和Redis协议流量的抓取(这当然不会是全部,后续会支持更多),并且支持各种过滤条件, 更多见 Github 文档:Kyanos命令详解Watch部分
总览全局-stat
仅有watch命令只能提供一个细粒度分析的视角,Stat则提供了更为灵活和高维度的分析能力,简单来说就是将请求响应的指标按照一些维度聚合起来,比如我想知道哪些远程ip的接口最慢,就通过聚合相同ip的请求响应来获取最慢的远程ip。
所以它能回答下面这些问题:
帮我找到现在这台机器上调用的哪些远程ip的HTTP接口最慢?
一行命令搞定:./kyanos stat http --side client -i 5 -m n -l 10 -g conn,每5秒输出请求响应在网络中的耗时最长的前10个HTTP连接,输出如下:
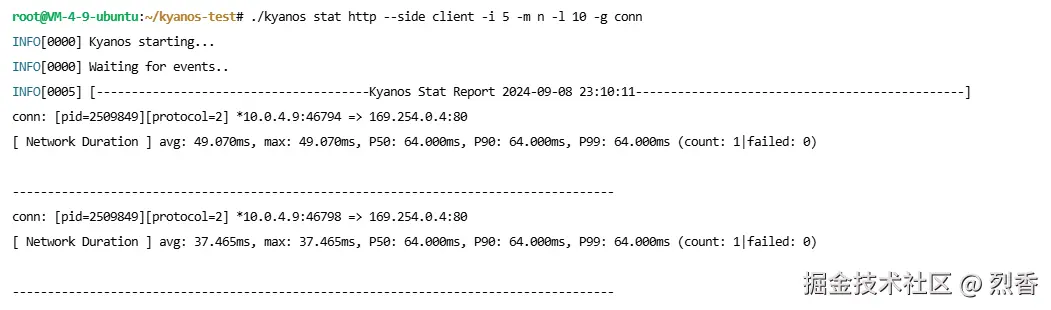
结果输出找到了两个连接,还有耗时的avg、max、pxx等信息。
我的机器出口流量非常大,到底哪些HTTP请求造成的?
一行命令搞定:./kyanos stat http --side client -i 5 -m p -s 10 -g none, 每5秒按输出响应大小最大的前10个HTTP请求响应, 输出如下:

可以看到结果中包含了响应的大小的 avg、max、pxx 等,还包含了 HTTP 请求的 path 信息。
使用stat命令的一般步骤
- 首先确定你关心的是什么指标,使用
--metrics指定。kyanos支持以下指标的聚合。
| 观测指标 | flag |
|---|---|
| 总耗时 | t |
| 响应数据大小 | p |
| 请求数据大小 | q |
| 在网络中的耗时 | n |
| 从Socket缓冲区读取的耗时 | s |
- 然后确定聚合的维度,使用
--group-by或者-g指定 。比如我们关注不同远程服务提供的服务质量是否有差异,就可以指定-g remote-ip,这样请求响应的统计信息就会按照不同的远程ip地址聚合,最终我们将会得到一个不同远程ip的耗时情况,更容易看出哪个远程服务存在问题。kyanos支持以下聚合方式:
| 聚合维度 | 值 |
|---|---|
| 最细的粒度,只聚合到单个连接 | conn |
| 远程ip | remote-ip |
| 远程端口 | remote-port |
| 本地端口 | local-port |
| 连接协议 | protocol |
| 最粗粒度,聚合所有的请求响应 | none |
更完整的使用说明见Github:https://github.com/hengyoush/kyanos
stat通过watch观察的结果,根据用户指定的聚合维度聚合(–group-by参数),最后按照用户最关心的指标输出(–metrics参数).
如果要用tcpdump该花多少时间啊,使用kyanos几秒就搞定了!
结语
啊其实有些标题党了~😄, kyanos 其实还不能真正取代 tcpdump,一方面是 kyanos 目前支持的应用层协议比较有限,对于网络环境更加复杂的部署的支持还有待改进,另外一方面 tcpdump 和 kyanos 的定位不太一样, kyanos更加侧重于问题排查。但总的来说,其确实能提高咱们业务开发的排查效率👍。
我为什么这么自信呢?因为我是用 kyanos 真正解决过问题 的,看过我文章的朋友可能知道我是搞 Redis 的(专栏:Redis疑难杂症 – 烈香的专栏,我的Blog:烈香的Blog),kyanos 帮我解决了一个非常诡异的 Redis 客户端超时但 Redis 服务端没有任何异常的问题(这个解决过程我近期会发一篇文章出来,感兴趣的朋友可以关注我哦~),这个问题在30min内排查出来定位到原因,kyanos 通过这一次真正验证了自身价值。所以我敢开源出来,我相信kyanos也能帮助到大家~
最后的最后可不可以点一个star鼓励我,哼,别逼我求你😡 Kyanos
我是烈香,我们下篇文章再见~
发表回复